Deep Learning
1. What is deep learning?

Deep learning is a type of machine learning that uses artificial neural networks to learn from data. Neural networks are inspired by the structure and function of the human brain. They are made up of layers of interconnected nodes, called neurons. Each neuron performs a simple mathematical operation on its inputs, and then passes the output to other neurons in the next layer.
Deep learning algorithms are able to learn complex patterns and relationships within data. They can be used to solve a wide range of problems, including:
- Image recognition: classifying images of objects, such as cars, animals, and faces.
- Natural language processing: understanding and generating human language.
- Machine translation: translating text from one language to another.
- Speech recognition: transcribing spoken language into text.
- Recommendation systems: recommending products, movies, and other items to users.
How does deep learning work?
Deep learning algorithms are trained on large datasets of labeled data. The data is used to teach the algorithm how to identify the patterns and relationships in the data. Once the algorithm is trained, it can be used to make predictions on new data.
The training process for deep learning algorithms is typically computationally expensive. This is because the algorithms need to process large amounts of data in order to learn. However, the training process can be accelerated using specialized hardware, such as GPUs.
The different types of deep learning algorithms
There are many different types of deep learning algorithms. Some of the most common types include:
- Convolutional neural networks (CNNs): CNNs are well-suited for image recognition tasks. They are able to learn the spatial relationships between pixels in images.
- Recurrent neural networks (RNNs): RNNs are well-suited for natural language processing tasks. They are able to learn the sequential dependencies between words in a sentence.
- Long short-term memory (LSTM) networks: LSTMs are a type of RNN that are particularly well-suited for learning long-range dependencies.
- Transformers: Transformers are a type of neural network that have recently been shown to achieve state-of-the-art results on a variety of natural language processing tasks.
Applications of deep learning
Deep learning is being used in a wide range of applications, including:
- Computer vision: Deep learning is used for tasks such as image recognition, object detection, and scene understanding.
- Natural language processing: Deep learning is used for tasks such as machine translation, speech recognition, and text summarization.
- Recommendation systems: Deep learning is used for tasks such as recommending products, movies, and other items to users.
- Medical imaging: Deep learning is used for tasks such as detecting cancer cells in medical images and diagnosing diseases.
- Finance: Deep learning is used for tasks such as stock market prediction and fraud detection.
Deep learning is a rapidly growing field with new applications being developed all the time. It is one of the most powerful machine learning techniques available today.
Machine Learning Basics
2. Machine Learning Basics

Supervised learning
Supervised learning is a type of machine learning where the algorithm is trained on a dataset of labeled data. The labeled data consists of input features and output targets. The algorithm learns to map the input features to the output targets.
Supervised learning algorithms can be used for both classification and regression tasks. In classification tasks, the algorithm learns to predict a discrete output, such as whether an email is spam or not spam. In regression tasks, the algorithm learns to predict a continuous output, such as the price of a house.
Some examples of supervised learning algorithms include:
- Linear regression
- Logistic regression
- Decision trees
- Support vector machines
- Random forests
- Gradient boosted trees
Unsupervised learning
Unsupervised learning is a type of machine learning where the algorithm is trained on a dataset of unlabeled data. The unlabeled data consists of input features only. The algorithm learns to identify patterns and relationships in the data without being told what to look for.
Unsupervised learning algorithms can be used for tasks such as:
- Clustering: grouping similar data together
- Anomaly detection: identifying unusual data points
- Dimensionality reduction: reducing the number of features in a dataset
- Association rule mining: finding patterns in data that occur together frequently
Some examples of unsupervised learning algorithms include:
- K-means clustering
- Hierarchical clustering
- Gaussian mixture models
- Principal component analysis
- t-distributed stochastic neighbor embedding
Reinforcement learning
Reinforcement learning is a type of machine learning where the algorithm learns to behave in an environment in order to maximize a reward. The algorithm is given a set of states, actions, and rewards. It learns to select actions that lead to higher rewards and avoid actions that lead to lower rewards.
Reinforcement learning algorithms can be used to train agents to play games, control robots, and make investment decisions.
Some examples of reinforcement learning algorithms include:
- Q-learning
- SARSA
- Policy gradients
- Actor-critic
Evaluation metrics
Evaluation metrics are used to assess the performance of machine learning models. Some common evaluation metrics include:
- Accuracy: the percentage of predictions that are correct
- Precision: the percentage of positive predictions that are actually positive
- Recall: the percentage of positive data points that are correctly predicted as positive
- F1 score: a harmonic mean of precision and recall
- Mean squared error (MSE): the average squared difference between the predicted and actual values
- Root mean squared error (RMSE): the square root of the MSE
- R-squared: a measure of how well the model explains the variation in the data
The best evaluation metric to use depends on the specific problem that is being solved. For example, accuracy is a good metric for classification tasks, but it can be misleading for imbalanced datasets.
I hope this provides a basic overview of machine learning. Please let me know if you have any other questions.
Neural Network Basics
3. Artificial neural networks
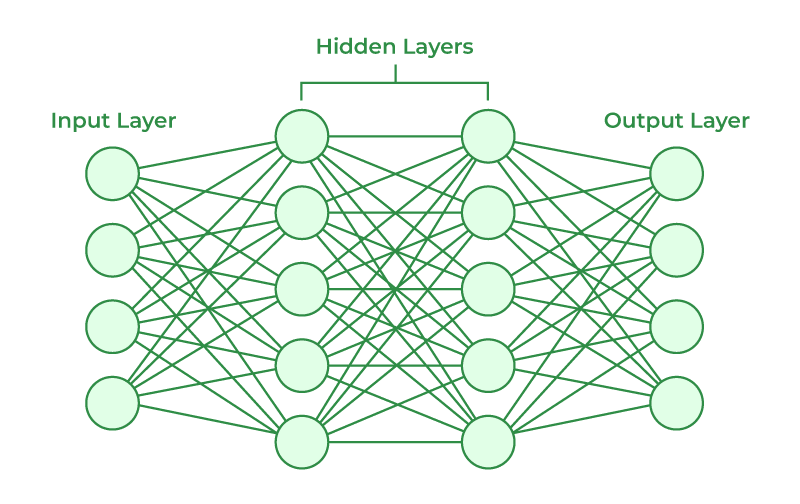
A neural network is a type of machine learning algorithm that is inspired by the structure and function of the human brain. Neural networks are made up of layers of interconnected nodes, called neurons. Each neuron performs a simple mathematical operation on its inputs, and then passes the output to other neurons in the next layer.
The simplest type of neural network is a feedforward neural network. In a feedforward neural network, the data flows in one direction, from the input layer to the output layer. Feedforward neural networks are typically used for classification and regression tasks.
More complex neural networks, such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs), can be used to solve more complex tasks, such as natural language processing and image recognition.
1.1 Activation Functions
Activation functions are used to introduce non-linearity into neural networks. This is important because it allows the network to learn more complex patterns in the data.
Some common activation functions include:
- Sigmoid function: The sigmoid function squashes its input to a value between 0 and 1. This makes it useful for classification tasks, where the output of the network needs to be a probability.
- Tanh function: The tanh function is similar to the sigmoid function, but it squashes its input to a value between -1 and 1. This makes it useful for regression tasks, where the output of the network can be a continuous value.
- ReLU function: The ReLU function (rectified linear unit) simply outputs its input if it is positive, and 0 if it is negative. This makes it efficient to compute and is often used in deep neural networks.
1.2 Loss Functions
Loss functions are used to measure how well a neural network is performing on a given task. The loss function is calculated on the output of the network and the ground truth labels.
Some common loss functions include:
- Cross-entropy loss: The cross-entropy loss is typically used for classification tasks. It measures how different the predicted probability distribution is from the ground truth distribution.
- Mean squared error (MSE): The MSE loss is typically used for regression tasks. It measures the average squared difference between the predicted values and the ground truth values.
1.3 Optimizers
Optimizers are used to update the weights of a neural network to minimize the loss function.
Some common optimizers include:
- Stochastic gradient descent (SGD): SGD is a simple but effective optimizer. It updates the weights of the network in the direction of the negative gradient of the loss function.
- Adam: Adam is a more advanced optimizer than SGD. It uses a variety of techniques to accelerate the training process.
The choice of activation function, loss function, and optimizer depends on the specific problem that is being solved.
I hope this provides a basic overview of the structure, activation functions, loss functions, and optimizers of artificial neural networks. Please let me know if you have any other questions.
CNN Architecture
4. Convolutional Neural Networks (CNNs)
.webp)
4.1 CNN Architecture
Convolutional neural networks (CNNs) are a type of neural network that is well-suited for image recognition tasks. CNNs are able to learn the spatial relationships between pixels in images. This allows them to identify objects and scenes in images even if they are rotated, scaled, or translated.
CNNs are typically made up of the following layers:
- Input layer: The input layer takes the image as input.
- Convolutional layers: Convolutional layers are the core building blocks of CNNs. They learn to identify features in the image by applying a set of filters to the image.
- Pooling layers: Pooling layers reduce the dimensionality of the image by downsampling it. This makes the network more efficient to train and helps to prevent overfitting.
- Fully connected layers: Fully connected layers are similar to the layers in a feedforward neural network. They learn to combine the features extracted by the convolutional and pooling layers to classify or detect objects in the image.
4.2 Pooling Layers
Pooling layers are used to reduce the dimensionality of the image and prevent overfitting. There are two main types of pooling layers: max pooling and average pooling.
Max pooling takes the maximum value of a small region of the image and outputs that value as a new pixel. This reduces the number of pixels in the image by a factor of the size of the region.
Average pooling takes the average value of a small region of the image and outputs that value as a new pixel. This also reduces the number of pixels in the image by a factor of the size of the region.
4.3 Convolutional Layers
Convolutional layers learn to identify features in the image by applying a set of filters to the image. Each filter is a small matrix of numbers. The filter is applied to the image by sliding it across the image and multiplying it with the underlying pixels. The output of the filter is a new image, called a feature map.
The feature map contains the responses of the filter to the different features in the image. For example, a filter might be designed to detect edges, so the feature map would contain the strength of the edges at each pixel in the image.
4.4 Fully Connected Layers
Fully connected layers are similar to the layers in a feedforward neural network. They learn to combine the features extracted by the convolutional and pooling layers to classify or detect objects in the image.
Each neuron in a fully connected layer is connected to every neuron in the previous layer. The neurons learn to combine the inputs from the previous layer to produce an output. The output of the fully connected layers is then used to classify or detect objects in the image.
CNNs have been shown to achieve state-of-the-art results on a variety of image recognition tasks, such as image classification, object detection, and image segmentation.
I hope this provides a basic overview of CNN architecture and the different types of layers that are used in CNNs. Please let me know if you have any other questions.
Recurrent Neural Networks (RNNs)
5. Recurrent Neural Networks (RNNs)
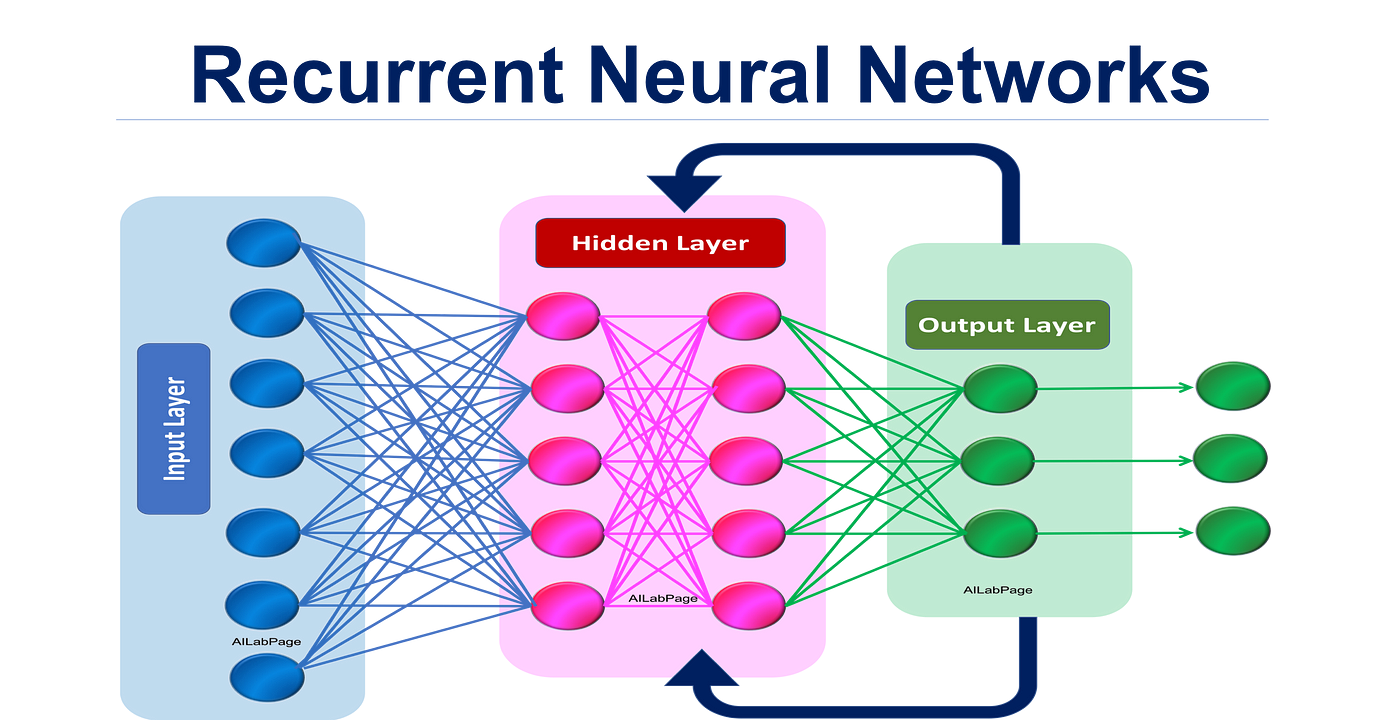
RNN Architecture
Recurrent neural networks (RNNs) are a type of neural network that are well-suited for sequential data, such as text and audio. RNNs are able to learn the long-term dependencies in sequential data. This allows them to solve tasks such as machine translation, speech recognition, and text generation.
RNNs are made up of recurrent units, which are connected in a sequence. Each recurrent unit takes an input and a hidden state as input and outputs a new hidden state. The hidden state contains information about the previous inputs to the recurrent unit.
The following is a diagram of a simple RNN architecture:
Input -> Recurrent Unit -> Recurrent Unit -> ... -> Recurrent Unit -> Output
LSTM Cells
Long short-term memory (LSTM) cells are a type of recurrent unit that are well-suited for learning long-term dependencies in sequential data. LSTM cells have three gates: an input gate, a forget gate, and an output gate.
The input gate controls how much of the new input is added to the hidden state. The forget gate controls how much of the previous hidden state is kept. The output gate controls how much of the hidden state is output.
The following is a diagram of an LSTM cell:
Input -> Input Gate -> Forget Gate -> Output Gate -> Hidden State -> Output
GRU Cells
Gated recurrent units (GRUs) are a type of recurrent unit that are similar to LSTM cells. GRUs have two gates: an update gate and a reset gate.
The update gate controls how much of the previous hidden state is kept. The reset gate controls how much of the new input is added to the hidden state.
The following is a diagram of a GRU cell:
Input -> Reset Gate -> Update Gate -> Hidden State -> Output
RNN Applications
RNNs are used in a variety of applications, including:
- Machine translation: RNNs are used to translate text from one language to another.
- Speech recognition: RNNs are used to transcribe spoken language into text.
- Text generation: RNNs are used to generate text, such as news articles and creative writing.
- Music generation: RNNs are used to generate music, such as melodies and harmonies.
- Video prediction: RNNs are used to predict future frames of a video sequence.
RNNs are a powerful tool for solving a variety of tasks involving sequential data.
I hope this provides a basic overview of RNN architecture, LSTM cells, and GRU cells. Please let me know if you have any other questions.
Training Deep Learning Models
6. Training Deep Learning Models
Overfitting and Underfitting
Overfitting and underfitting are two common problems that can occur when training deep learning models.
Overfitting occurs when the model learns the training data too well and is unable to generalize to new data. This can happen if the model has too many parameters or if the training data is too small.
Underfitting occurs when the model does not learn the training data well enough and is unable to make accurate predictions on either the training data or new data. This can happen if the model has too few parameters or if the training data is too noisy.
Data Augmentation
Data augmentation is a technique that can be used to reduce overfitting. It involves creating new training data by applying transformations to the existing training data. For example, data augmentation can be used to create new images by rotating, cropping, and flipping existing images.
Regularization Techniques
Regularization techniques are another way to reduce overfitting. They involve penalizing the model for having complex parameters, forcing it to learn simpler patterns in the data, which improves generalization performance.
Some common regularization techniques include:
- L1 regularization: Penalizes the model for having large weights, forcing it to learn sparser parameters.
- L2 regularization: Penalizes the model for having large squared weights, forcing it to learn smoother parameters.
- Dropout: Randomly drops out neurons during training, forcing the model to learn redundant features.
Batch Normalization
Batch normalization is a technique that can be used to improve the performance of deep learning models and reduce overfitting. It normalizes the inputs of each layer in the model, stabilizing the training process and improving generalization performance.
Batch normalization works by normalizing the inputs of each layer to have a mean of zero and a standard deviation of one, improving the stability of the training process.
Batch normalization has been shown to be effective in improving the performance of deep learning models on various tasks, such as image classification, object detection, and natural language processing.
I hope this provides a basic overview of overfitting, underfitting, data augmentation, regularization techniques, and batch normalization. Please let me know if you have any other questions.
Evaluating Deep Learning Models
7. Evaluating Deep Learning Models

Model saving and loading
Once a deep learning model has been trained, it is important to evaluate its performance on a held-out test set. This is done to ensure that the model is able to generalize to new data and is not simply overfitting to the training data.
A common way to evaluate a deep learning model is to use a train-validation-test split. In a train-validation-test split, the training data is split into three sets:
- Training set: The training set is used to train the model.
- Validation set: The validation set is used to tune the model's hyperparameters and to evaluate the model's performance on data that it has not seen before.
- Test set: The test set is used to evaluate the final performance of the model.
The training set should be the largest of the three sets, as this will give the model the most data to learn from. The validation and test sets should be of equal size.
Confusion Matrices
A confusion matrix is a table that shows the predicted and actual values for a classification model. The rows of the confusion matrix represent the actual values, and the columns represent the predicted values.
Predicted | Actual
---------|--------
Positive | Positive | True Positive (TP) | False Negative (FN)
Negative | Positive | False Positive (FP) | True Negative (TN)
Precision, Recall, and F1 Score
Precision, recall, and F1 score are three metrics that are commonly used to evaluate the performance of classification models.
Precision is the fraction of predicted positives that are actually positive. It is calculated as follows:
Precision = TP / (TP + FP)
Recall is the fraction of actual positives that are correctly predicted. It is calculated as follows:
Recall = TP / (TP + FN)
F1 Score is a harmonic mean of precision and recall. It is calculated as follows:
F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
Precision, recall, and F1 score can all be calculated for individual classes or for the overall model.
Conclusion
Train-validation-test split, confusion matrices, precision, recall, and F1 score are all important tools for evaluating the performance of deep learning models. By using these tools, we can ensure that our models are able to generalize to new data and make accurate predictions.
Model Saving and Loading
8. Deploying deep learning models
Once a deep learning model has been trained, it needs to be saved so that it can be used to make predictions on new data. There are a number of different ways to save a deep learning model, depending on the framework that is being used.
For example, in TensorFlow, models can be saved to SavedModel format. SavedModel format is a cross-platform format that can be used to load models in other frameworks, such as PyTorch and ONNX.
Once a model has been saved, it can be loaded back into the framework and used to make predictions on new data.
Serving Deep Learning Models
There are a number of different ways to serve deep learning models. One common approach is to use a REST API. A REST API allows clients to send requests to the model and receive predictions in response.
Another approach to serving deep learning models is to use a model server. A model server is a specialized server that is designed to serve deep learning models. Model servers can provide a number of features, such as scalability and fault tolerance.
Conclusion
Model saving and loading and serving deep learning models are important steps in the deployment of deep learning models. By following these steps, we can make our models available to users so that they can be used to make predictions on new data.
Here are some additional tips for deploying deep learning models:
- Choose the right deployment platform. There are a number of different cloud-based and on-premises platforms that can be used to deploy deep learning models. Choose a platform that meets your specific needs, such as scalability, performance, and cost.
- Optimize your model for deployment. Once you have chosen a deployment platform, you may need to optimize your model for deployment. This may involve reducing the size of the model or converting the model to a different format.
- Monitor your model in production. Once your model is deployed in production, it is important to monitor its performance and make sure that it is still meeting your needs. You can use monitoring tools to track the accuracy, latency, and resource usage of your model.
Transfer Learning
9. Transfer learning
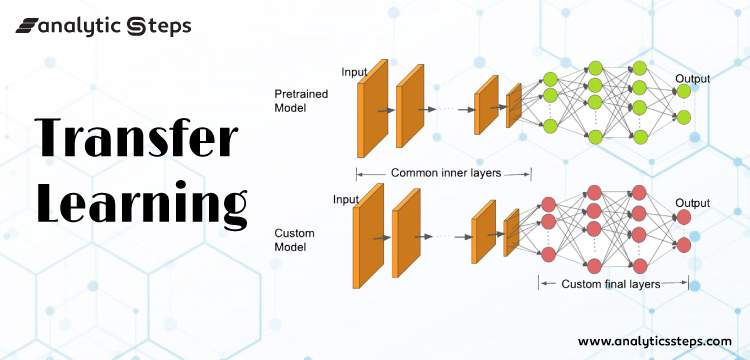
What is Transfer Learning?
Transfer learning is a machine learning technique where a model developed for one task is reused as the starting point for a model on a second task. This can be useful when the second task is related to the first task, but it is too expensive or time-consuming to train a model from scratch.
For example, a model trained to classify images of cats and dogs could be reused as the starting point for a model to classify images of different types of flowers. The first model would have already learned some general features that are useful for image classification, such as how to identify edges and shapes. The second model could then focus on learning the specific features that are most useful for distinguishing between different types of flowers.
How to use Transfer Learning in Deep Learning
- Choose a pre-trained model that is related to the task that you want to solve.
- Remove the output layer of the pre-trained model.
- Add a new output layer that is specific to the task that you want to solve.
- Fine-tune the pre-trained model on your own data.
This process is often referred to as "fine-tuning". Fine-tuning is typically much faster and less computationally expensive than training a model from scratch.
Examples of Transfer Learning in Deep Learning
Transfer learning is widely used in deep learning for a variety of tasks, including:
- Image classification: Pre-trained models such as VGG16 and ResNet50 are often used as the starting point for image classification tasks.
- Object detection: Pre-trained models such as Faster R-CNN and Mask R-CNN are often used as the starting point for object detection tasks.
- Natural language processing: Pre-trained models such as BERT and GPT-3 are often used as the starting point for natural language processing tasks such as machine translation and text summarization.
Benefits of Transfer Learning
Transfer learning offers a number of benefits, including:
- Faster training: Transfer learning can significantly reduce the time required to train a deep learning model.
- Improved performance: Transfer learning can lead to improved performance on a variety of tasks, especially when the target task is similar to the source task.
- Reduced data requirements: Transfer learning can reduce the amount of data required to train a deep learning model. This is because the pre-trained model has already learned some general features that are useful for the task at hand.
Conclusion
Transfer learning is a powerful technique that can be used to improve the performance and reduce the training time of deep learning models. If you are working on a deep learning task, I encourage you to consider using transfer learning.
Deep Learning Frameworks Comparison
10. Deep learning frameworks

Deep Learning Frameworks Comparison
TensorFlow, PyTorch, and Keras are three of the most popular deep learning frameworks. Each framework has its own strengths and weaknesses, so it is important to choose the right framework for your needs.
TensorFlow
TensorFlow is an open-source software library for numerical computation using data flow graphs. It is developed by Google and is used by researchers and engineers alike to train and deploy machine learning models.
TensorFlow is known for its flexibility and scalability. It can be used to train models of all sizes, from simple regression models to complex neural networks. TensorFlow also supports a wide range of hardware platforms, including CPUs, GPUs, and TPUs.
However, TensorFlow can be complex to learn and use. It has a steep learning curve, and it can be difficult to debug TensorFlow code.
PyTorch
PyTorch is an open-source machine learning framework that is based on the Torch library. It is developed by Facebook and is known for its simplicity and ease of use.
PyTorch has a Pythonic API, which makes it easy to learn and use for Python developers. PyTorch also supports dynamic computation graphs, which makes it easy to experiment with different model architectures and training algorithms.
However, PyTorch is not as scalable as TensorFlow. It can be difficult to train large models on PyTorch, and it does not support as many hardware platforms as TensorFlow.
Keras
Keras is a high-level API for TensorFlow and PyTorch. It is designed to make it easy to build and train deep learning models.
Keras provides a number of features that make it easy to build and train deep learning models, including:
- A pre-built library of common model architectures
- A simple API for building custom model architectures
- A number of built-in optimizers, loss functions, and evaluation metrics
Keras is a good choice for beginners and experienced deep learning practitioners alike. It is easy to learn and use, and it supports a wide range of tasks, including image classification, object detection, and natural language processing.
Choosing a deep learning framework
The best deep learning framework for you will depend on your specific needs. If you are a beginner, I recommend starting with Keras. It is easy to learn and use, and it supports a wide range of tasks.
If you are an experienced deep learning practitioner, you may want to consider using TensorFlow or PyTorch. These frameworks are more flexible and scalable than Keras, but they can be more difficult to learn and use.
| Feature |
TensorFlow |
PyTorch |
Keras |
| Flexibility |
Very high |
Very high |
High |
| Scalability |
Very high |
High |
Medium |
| Ease of use |
Medium |
High |
Very high |
| Learning curve |
Steep |
Moderate |
Low |
| Support for hardware platforms |
Wide |
Wide |
Limited |
| Pre-built library of model architectures |
Yes |
Yes |
Yes |
| Support for custom model architectures |
Yes |
Yes |
Yes |
| Support for optimizers, loss functions, and evaluation metrics |
Yes |
Yes |
Yes |
I hope this helps you choose the right deep learning framework for your needs.
Computer Vision with Deep Learning
11. Deep learning for computer vision
Computer Vision with Deep Learning
Deep learning has revolutionized the field of computer vision in recent years. Deep learning models are now able to achieve state-of-the-art results on a variety of computer vision tasks, including image classification, object detection, and semantic segmentation.
Image Classification
Image classification is the task of assigning a label to an image. For example, an image classification model could be trained to distinguish between images of cats and dogs, or images of different types of flowers.
Deep learning models for image classification are typically based on convolutional neural networks (CNNs). CNNs are able to learn the spatial relationships between pixels in images, which makes them well-suited for image classification tasks.
Object Detection
Object detection is the task of identifying and localizing objects in an image. For example, an object detection model could be trained to detect the presence of cars and pedestrians in an image, or to detect the different types of objects in a grocery store shelf.
Deep learning models for object detection are typically based on CNNs and region proposal networks (RPNs). RPNs are able to identify regions of an image that are likely to contain objects. The CNN is then used to classify the objects in the regions proposed by the RPN.
Semantic Segmentation
Semantic segmentation is the task of assigning a label to each pixel in an image. For example, a semantic segmentation model could be trained to label each pixel in an image as either a cat, a dog, or the background.
Deep learning models for semantic segmentation are typically based on CNNs and encoder-decoder architectures. The encoder compresses the input image into a latent representation, and the decoder decompresses the latent representation into a segmentation map.
Conclusion
Deep learning has revolutionized the field of computer vision. Deep learning models are now able to achieve state-of-the-art results on a variety of computer vision tasks, including image classification, object detection, and semantic segmentation.
Deep learning models are used in a wide range of applications, such as self-driving cars, medical imaging, and robotics. As deep learning models continue to improve, we can expect to see even more innovative and groundbreaking applications in the future.
Natural Language Processing with Deep Learning
12. Deep learning for natural language processing

Natural Language Processing with Deep Learning
Deep learning has also revolutionized the field of natural language processing (NLP). Deep learning models are now able to achieve state-of-the-art results on a variety of NLP tasks, including text classification, machine translation, and question answering.
Text Classification
Text classification is the task of assigning a label to a text document. For example, a text classification model could be trained to distinguish between news articles about politics and sports, or to identify spam emails.
Deep learning models for text classification are typically based on recurrent neural networks (RNNs) and long short-term memory (LSTM) cells. RNNs are able to learn the temporal relationships between words in a text document, which makes them well-suited for text classification tasks. LSTM cells are a type of RNN that are well-suited for learning long-term dependencies in text data.
Machine Translation
Machine translation is the task of translating text from one language to another. For example, a machine translation model could be used to translate English text to Spanish text, or Chinese text to Japanese text.
Deep learning models for machine translation are typically based on encoder-decoder architectures. The encoder compresses the input text into a latent representation, and the decoder decompresses the latent representation into the translated text.
Question Answering
Question answering is the task of answering questions about a given text document. For example, a question answering model could be used to answer questions about a news article, or to answer questions about a product description.
Deep learning models for question answering are typically based on RNNs and LSTMs. The model is first trained to read and understand the input text document. Once the model has understood the text document, it is able to answer questions about the text document.
Conclusion
Deep learning has revolutionized the field of NLP. Deep learning models are now able to achieve state-of-the-art results on a variety of NLP tasks, including text classification, machine translation, and question answering.
Deep learning models are used in a wide range of applications, such as machine translation tools, chatbots, and virtual assistants. As deep learning models continue to improve, we can expect to see even more innovative and groundbreaking applications in the future.
Reinforcement Learning with Deep Learning
13. Deep learning for reinforcement learning
What is reinforcement learning?
Reinforcement learning (RL) is a type of machine learning where an agent learns to behave in an environment by trial and error. The agent receives rewards for taking actions that lead to desired outcomes and penalties for taking actions that lead to undesired outcomes. Over time, the agent learns to take the actions that maximize its rewards.
How to use deep learning in reinforcement learning
Deep learning can be used to accelerate the training process of RL agents. Deep learning models can learn complex patterns in the environment and make predictions about the rewards that the agent will receive for taking different actions. This information can be used to guide the agent's exploration of the environment and help it to learn more quickly.
One common way to use deep learning in RL is to use a deep Q-network (DQN). A DQN is a type of neural network that learns to predict the expected reward for taking each possible action in the current state of the environment. The agent can then use this information to select the action that is expected to maximize its reward.
Another common way to use deep learning in RL is to use a policy gradient method. Policy gradient methods directly optimize the policy of the agent, which is the function that maps from states to actions. Policy gradient methods can learn more complex policies than DQNs, but they can be more difficult to train.
Benefits of using deep learning in reinforcement learning
There are a number of benefits to using deep learning in RL, including:
- Faster training: Deep learning can accelerate the training process of RL agents.
- Better performance: Deep learning can help RL agents to learn more complex policies and achieve better performance on complex tasks.
- More generalizable solutions: Deep learning can help RL agents to learn more generalizable solutions that can be applied to new environments and tasks.
Conclusion
Deep learning is a powerful tool that can be used to improve the performance and efficiency of RL agents. Deep learning is used in a wide range of RL applications, such as game playing, robot control, and financial trading. As deep learning continues to develop, we can expect to see even more innovative and groundbreaking applications of deep learning in RL.
Advanced Deep Learning Topics
14. Advanced deep learning topics
Generative adversarial networks (GANs)
Generative adversarial networks (GANs) are a type of deep learning model that can be used to generate realistic data. GANs are composed of two neural networks: a generator and a discriminator. The generator learns to generate new data, while the discriminator learns to distinguish between real data and generated data.
GANs have been used to generate realistic images, videos, text, and even music. GANs are also being used to develop new medical treatments and to improve the performance of other machine learning models.
Attention mechanisms
Attention mechanisms are a type of neural network architecture that allows models to focus on specific parts of an input sequence. Attention mechanisms are commonly used in natural language processing (NLP) models, such as machine translation and question answering models.
Attention mechanisms have been shown to improve the performance of NLP models on a variety of tasks. For example, attention mechanisms have been shown to improve the accuracy of machine translation models and question answering models.
Capsule networks
Capsule networks are a type of neural network that were designed to address the limitations of convolutional neural networks (CNNs). CNNs are typically used for image classification and object detection tasks. However, CNNs can have difficulty distinguishing between objects that are similar in appearance.
Capsule networks have been shown to outperform CNNs on a variety of image classification and object detection tasks. For example, capsule networks have been shown to be more accurate at distinguishing between different types of flowers and different types of birds.
Conclusion
GANs, attention mechanisms, and capsule networks are three advanced deep learning topics that are being used to develop new and innovative machine learning models. GANs are being used to generate realistic data, attention mechanisms are being used to improve the performance of NLP models, and capsule networks are being used to improve the performance of image classification and object detection models.
15. Conclusion
Deep learning is a powerful machine learning technique that has revolutionized many fields, including computer vision, natural language processing, and reinforcement learning. Deep learning models have achieved state-of-the-art results on a variety of tasks, such as image classification, object detection, machine translation, and question answering.
The future of deep learning is very bright. Deep learning models are becoming increasingly powerful and efficient, and they are being used to solve new and challenging problems all the time.
Trends in the Future of Deep Learning:
- More powerful and efficient deep learning models: Deep learning models are becoming increasingly powerful and efficient, thanks to advances in hardware and software. This is enabling deep learning to be used to solve more complex problems and to be deployed on a wider range of devices.
- More widespread adoption of deep learning: Deep learning is becoming more and more widely adopted in industry and academia. As more people learn about deep learning and its benefits, we can expect to see even more innovative and groundbreaking applications in the future.
- New and emerging deep learning applications: Deep learning is being used to solve new and emerging problems all the time. For example, deep learning is being used to develop self-driving cars, improve medical diagnosis, and create new forms of art and entertainment.
Examples of Deep Learning Applications:
- Computer vision: Deep learning is being used to develop self-driving cars, improve medical imaging, and develop new features for smartphones and other devices. For example, deep learning is being used to develop facial recognition systems that can be used to unlock smartphones and to identify people in security footage.
- Natural language processing: Deep learning is being used to develop machine translation tools, chatbots, and virtual assistants. For example, deep learning is being used to develop machine translation tools that can translate text between any two languages with high accuracy.
- Reinforcement learning: Deep learning is being used to develop agents that can play games, control robots, and manage financial portfolios. For example, deep learning is being used to develop agents that can play games at a superhuman level, such as AlphaGo and AlphaZero.
Deep learning is a powerful tool that is rapidly transforming the world around us. As deep learning continues to develop, we can expect to see even more innovative and groundbreaking applications in the future.
Deep Learning Resources
Deep Learning Resources
Course
- Machine Learning by Stanford University on Coursera: This course provides an introduction to machine learning, including deep learning.
- Deep Learning by Andrew Ng on Coursera: This course is a specialization that covers the fundamentals of deep learning, including neural networks, convolutional neural networks, and recurrent neural networks.
- Deep Learning with TensorFlow by Google AI on Coursera: This course focuses on using TensorFlow to build and train deep learning models.
Reference Links
- Deep Learning Book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville: This book is a comprehensive overview of deep learning.
- TensorFlow Documentation: The TensorFlow documentation is a great resource for learning about TensorFlow and how to use it to build and train deep learning models.
- PyTorch Documentation: The PyTorch documentation is a great resource for learning about PyTorch and how to use it to build and train deep learning models.


Comments
Post a Comment